
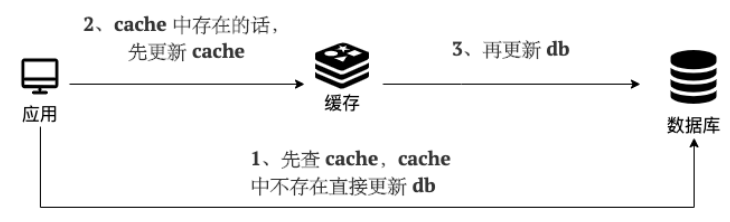
缓存读写策略
Cache Aside Pattern(旁路缓存模式)Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。 Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 db 的结果为准。 下面我们来看一下这个策略模式下的缓存读写步骤。 写: 先更新 db 然后直接删除 cache 。 简单画了一张图帮助大家理解写的步骤。 读 : 从 cache 中读取数据,读取到就直接返回 cache 中读取不到的话,就从 db 中读取数据返回 再把数据放到 cache 中 简单画了一张图帮助大家理解读的步骤。 你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。 比如说面试官很可能会追问:“在写数据的过程中,可以先删除 cache ,后更新 db 么?” 答案: 那肯定是不行的!因为这样可能会造成 数据库(db)和缓存(Cache)数据不一致的问题。 这个过程可以简单描述为: 如果有 2 个线程要并发「读写」数据,可能会发生以下场景: 线程 A 要更新 X =...
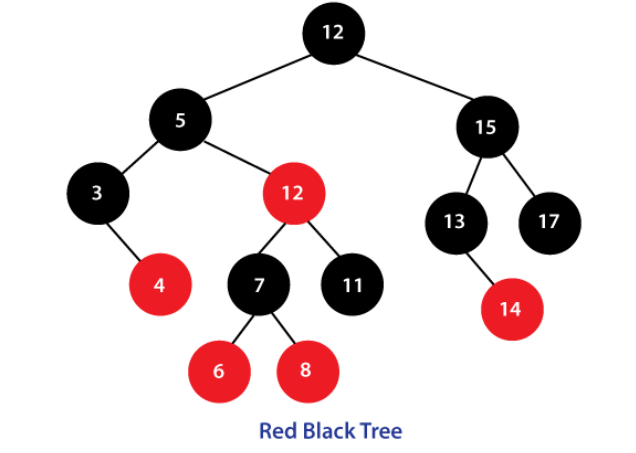
索引底层数据结构选型
1.Hash表哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。 为何能够通过 key 快速取出 value 呢? 原因在于 哈希算法(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value 哈希算法有个 Hash 冲突 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 链地址法。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 HashMap 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后HashMap为了减少链表过长的时候搜索时间过长引入了红黑树。 为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。 MySQL 的 InnoDB 存储引擎不直接支持常规的哈希索引,但是,InnoDB 存储引擎中存在一种特殊的“自适应哈希索引”(Adaptive Hash...
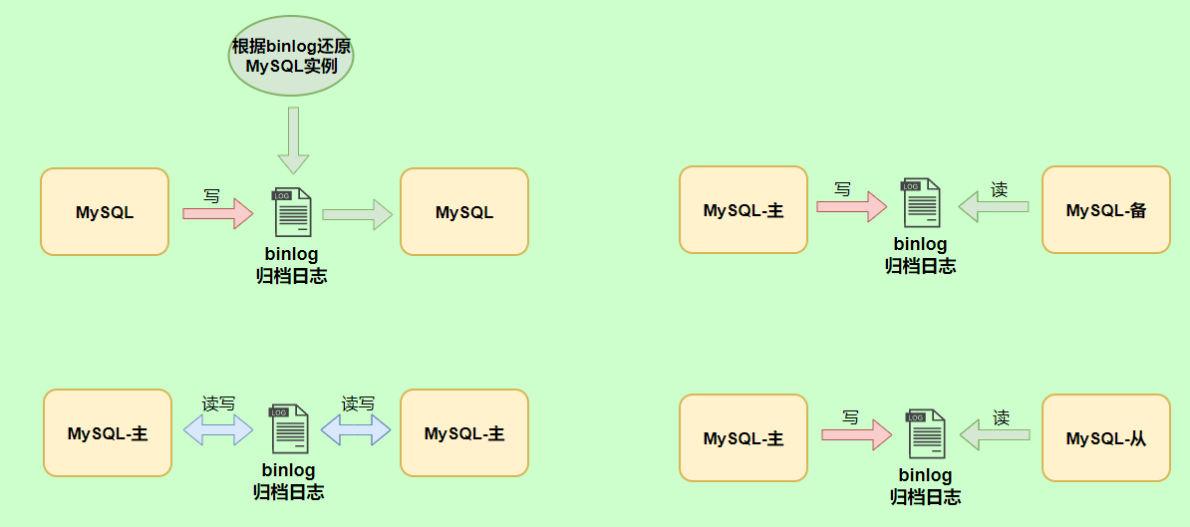
MySQL三大日志详解
redo log(崩溃恢复)redo log(重做日志)是 InnoDB 存储引擎独有的,它让 MySQL 拥有了崩溃恢复能力。 比如 MySQL 实例挂了或宕机了,重启时,InnoDB 存储引擎会使用 redo log 恢复数据,保证数据的持久性与完整性。 MySQL 中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到 Buffer Pool 中。 后续的查询都是先从 Buffer Pool 中找,没有命中再去硬盘加载,减少硬盘 IO 开销,提升性能。 更新表数据的时候,也是如此,发现 Buffer Pool 里存在要更新的数据,就直接在 Buffer Pool 里更新。 然后会把“在某个数据页上做了什么修改”记录到重做日志缓存(redo log buffer)里,接着刷盘到 redo log 文件里 理想情况,事务一提交就会进行刷盘操作,但实际上,刷盘的时机是根据策略来进行的。 小贴士:每条 redo 记录由“表空间号+数据页号+偏移量+修改数据长度+具体修改的数据”组成 刷盘时机InnoDB...
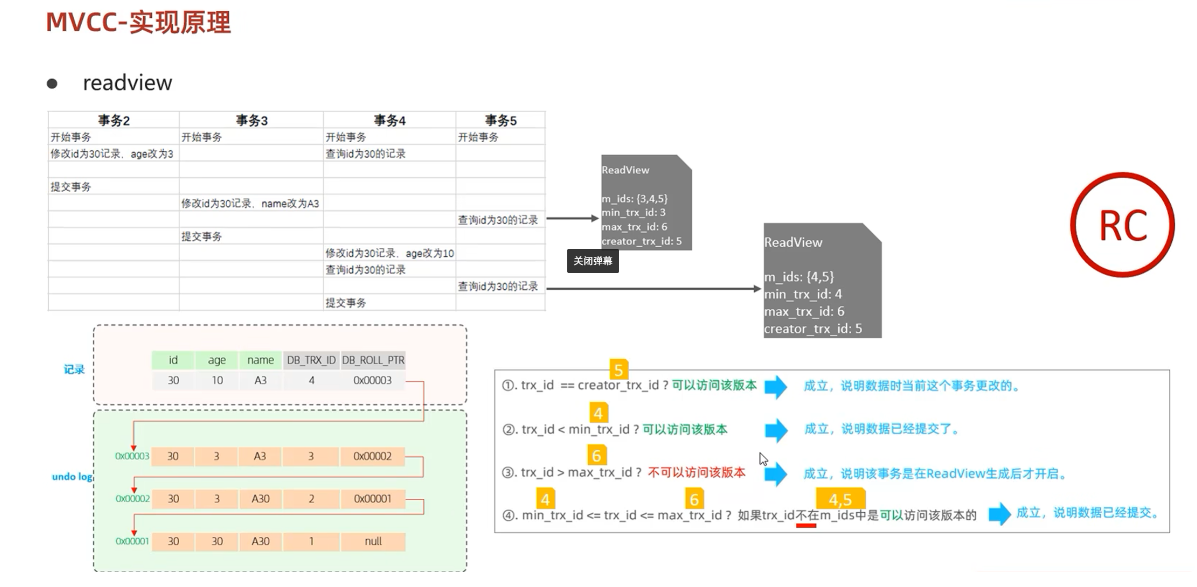
MVCC
当前读与快照读1.当前读 读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:select .. lock in share mode(共享锁), select…for update、update、insert、delete(排他锁)都是一种当前读。 2.快照读 简单的select(不加锁)就是快照读,快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。 Read Committed:每次select,都生成一个快照读。 Repeatable Read:开启事务后第一个select语句才是快照读的地方。 Serializable:快照读会退化为当前读。 3.MVCC 全称 Multi-Version Concurrency...

数据库范式
数据库的三范式(Normalization)是用于设计关系型数据库的标准,旨在减少数据冗余和提高数据一致性。三范式包括以下内容: 1.第一范式(1NF)定义:一个表格符合第一范式,如果它的每个字段都是原子的,即每个字段的值都是不可再分的基本数据项。 要求: 每列中的数据必须是不可分割的原子值。 每行必须是唯一的,可以通过主键来标识。 示例: 不符合 1NF 的表: 学生ID 姓名 课程 1 张三 数学, 语文 符合 1NF 的表: 学生ID 姓名 课程 1 张三 数学 1 张三 语文 2.第二范式(2NF)定义:一个表格符合第二范式,如果它首先符合第一范式,并且所有非主键列完全依赖于主键,而不是部分依赖。 要求: 消除部分依赖,即非主键属性必须依赖于整个主键,而不是主键的一部分。 示例: 不符合 2NF 的表: 学生ID 课程 教师 1 数学 李老师 1 语文 王老师 在这个例子中,教师依赖于课程而不是学生ID,因此存在部分依赖。 符合 2NF...
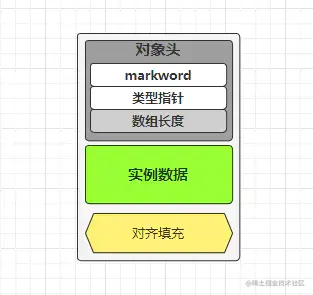
对象的内存布局
在 Hotspot 虚拟机中,对象在内存中的布局可以分为 3 块区域:对象头、实例数据、对齐填充。 对象头包括两部分信息: 标记字段:用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等等。 类型指针:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。 实例数据部分是对象真正存储的有效信息,也是在程序中所定义的各种类型的字段内容。 对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。 因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2...
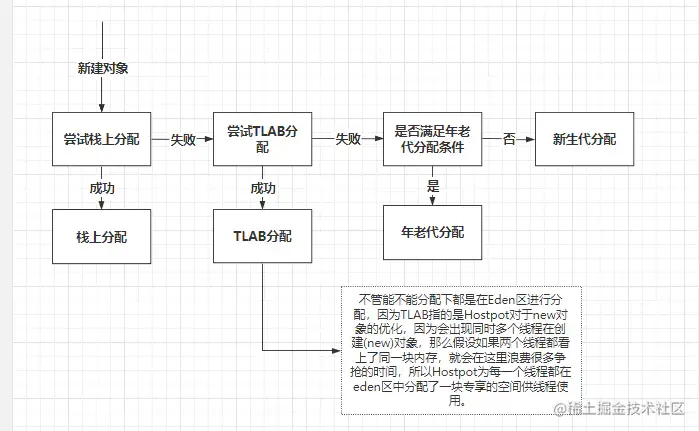
对象的创建
Step1:类加载检查虚拟机遇到一条 new...
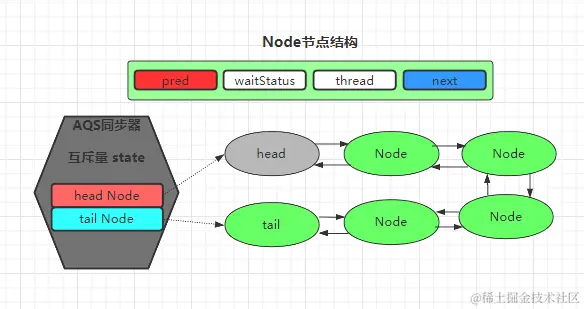
细聊AQS
AQS是什么?AQS 的全称为 AbstractQueuedSynchronizer ,翻译过来的意思就是抽象队列同步器 AQS 就是一个抽象类,主要用来构建锁和同步器。 AQS 是 Java 中实现各种同步器的基础框架,它提供了一套通用的机制来管理线程的等待和唤醒,从而实现对共享资源的安全访问。AQS 的核心在于同步状态的管理以及等待队列的维护,这使得它成为了 Java 并发编程中非常重要的工具。 AQS 为构建锁和同步器提供了一些通用功能的实现,因此,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 ReentrantLock,Semaphore,其他的诸如 ReentrantReadWriteLock,SynchronousQueue等等皆是基于 AQS...
线程池中线程异常后,销毁还是复用?
需要分两种情况: 使用execute()提交任务:当任务通过execute()提交到线程池并在执行过程中抛出异常时,如果这个异常没有在任务内被捕获,那么该异常会导致当前线程终止,并且异常会被打印到控制台或日志文件中。线程池会检测到这种线程终止,并创建一个新线程来替换它,从而保持配置的线程数不变。 使用submit()提交任务:对于通过submit()提交的任务,如果在任务执行中发生异常,这个异常不会直接打印出来。相反,异常会被封装在由submit()返回的Future对象中。当调用Future.get()方法时,可以捕获到一个ExecutionException。在这种情况下,线程不会因为异常而终止,它会继续存在于线程池中,准备执行后续的任务。 简单来说:使用execute()时,未捕获异常导致线程终止,线程池创建新线程替代;使用submit()时,异常被封装在Future中,线程继续复用。 这种设计允许submit()提供更灵活的错误处理机制,因为它允许调用者决定如何处理异常,而execute()则适用于那些不需要关注执行结果的场景。 在 Java 的...

线程池常见参数有哪些?如何解释?
在Java中,线程池是通过 java.util.concurrent 包中的 ThreadPoolExecutor 类来实现的。创建线程池时可以指定多个参数来控制线程池的行为和性能。以下是 ThreadPoolExecutor 的主要参数及其功能: 核心参数 corePoolSize(核心线程数) 功能:线程池中始终保持的最小线程数,即使这些线程处于空闲状态。 说明:当有新任务提交时,如果当前运行的线程少于 corePoolSize,则创建新线程来处理任务。 maximumPoolSize(最大线程数) 功能:线程池允许创建的最大线程数。 说明:当有新任务提交时,如果当前运行的线程数达到 corePoolSize 并且队列已满,则创建新线程来处理任务,直到达到 maximumPoolSize。 keepAliveTime(线程空闲保持时间) 功能:当线程池中的线程数超过 corePoolSize 时,多余的空闲线程的存活时间。 说明:超过这个时间的空闲线程会被终止和移出线程池。 unit(时间单位) 功能:用于指定 keepAliveTime...