ConcurrentHashMap全解
ConcurrentHashMap的结构
JDK8之前: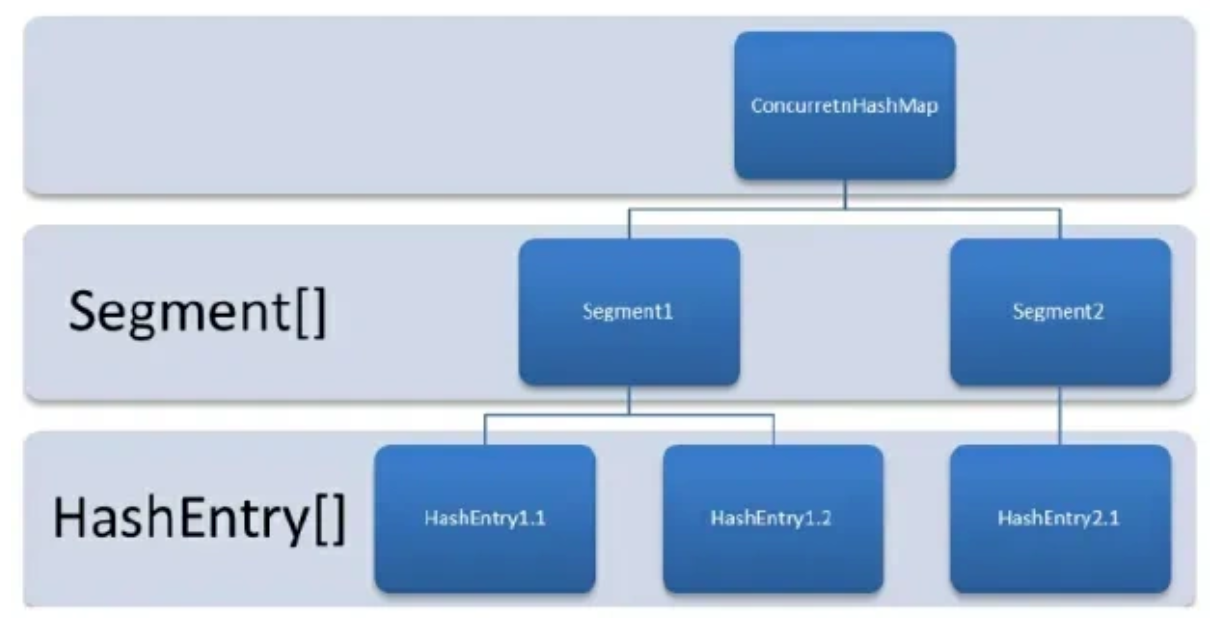
一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素
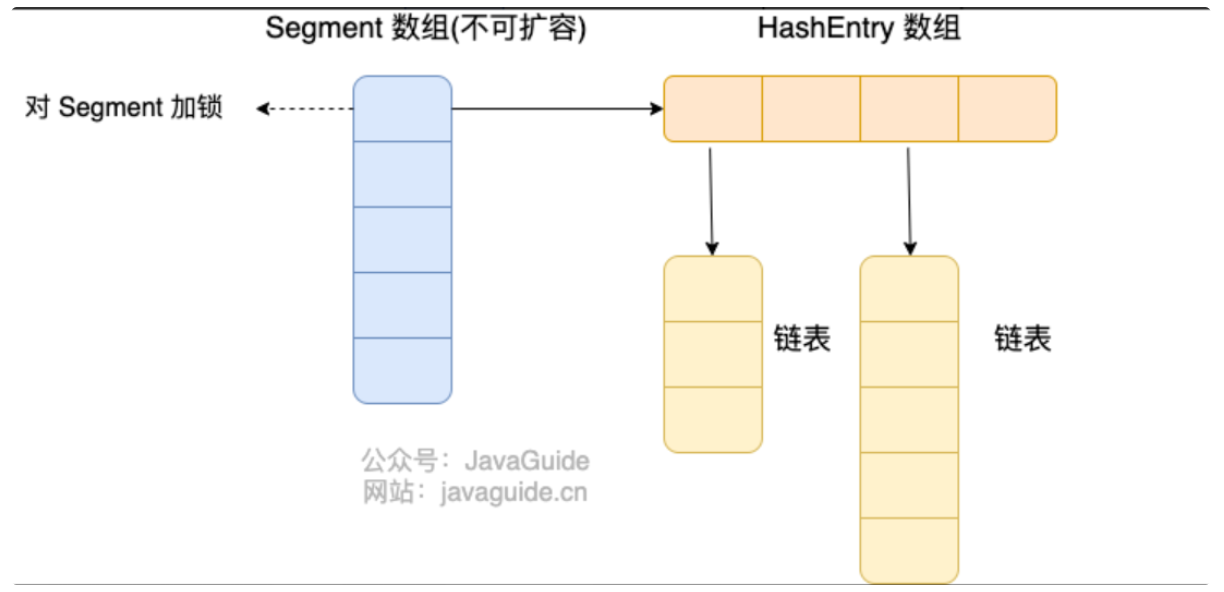
首先将数据分为一段一段(这个“段”就是 Segment)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
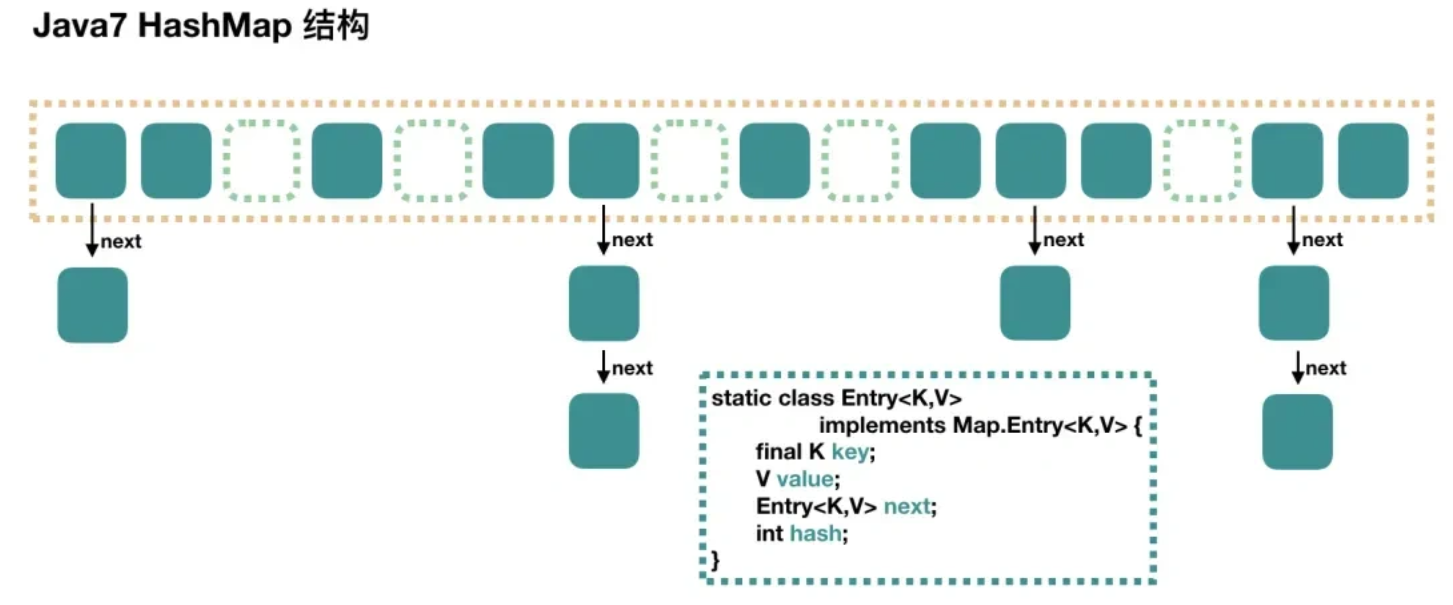
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。HashEntry 用于存储键值对数据。
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的个数一旦初始化就不能改变。 Segment 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。
Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。也就是说,对同一 Segment 的并发写入会被阻塞,不同 Segment 的写入是可以并发执行的。
JDK1.8 之后
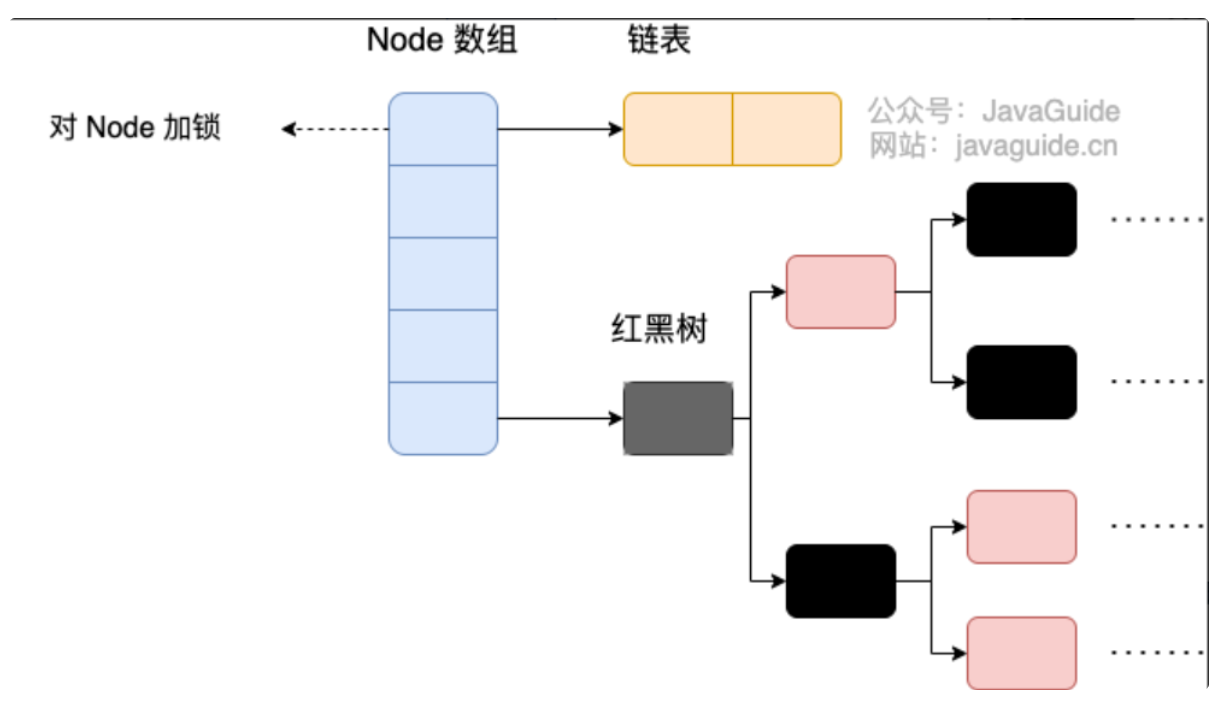
Java 8 几乎完全重写了 ConcurrentHashMap,代码量从原来 Java 7 中的 1000 多行,变成了现在的 6000 多行。
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全。数据结构跟 HashMap 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。当红黑树中的节点个数减少到 6 时,会退化成链表。
-CAS 操作:在更新数组引用等操作中,会使用比较并交换(Compare and Swap,CAS)操作来保证原子性。CAS 操作可以在不使用锁的情况下,实现对共享变量的原子更新,从而进一步提高了性能。
Java 8 中,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升
ConcurrentHashMap 和 HashTable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
1.底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟 HashMap1.8 的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
2.实现线程安全的方式(重要):
- 在 JDK1.7 的时候,
ConcurrentHashMap对整个桶数组进行了分割分段(Segment,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 - 到了 JDK1.8 的时候,
ConcurrentHashMap已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本; Hashtable(同一把锁) :使用synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
ConcurrentHashMap 为什么 key 和 value 不能为 null?
ConcurrentHashMap 的 key 和 value 不能为 null 主要是为了避免二义性。null 是一个特殊的值,表示没有对象或没有引用。如果你用 null 作为键,那么你就无法区分这个键是否存在于 ConcurrentHashMap 中,还是根本没有这个键。同样,如果你用 null 作为值,那么你就无法区分这个值是否是真正存储在 ConcurrentHashMap 中的,还是因为找不到对应的键而返回的。
拿 get 方法取值来说,返回的结果为 null 存在两种情况:
- 值没有在集合中 ;
- 值本身就是 null。
这也就是二义性的由来。
多线程环境下,存在一个线程操作该 ConcurrentHashMap 时,其他的线程将该 ConcurrentHashMap 修改的情况,所以无法通过 containsKey(key) 来判断否存在这个键值对,也就没办法解决二义性问题了。
与此形成对比的是,HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个。如果传入 null 作为参数,就会返回 hash 值为 0 的位置的值。单线程环境下,不存在一个线程操作该 HashMap 时,其他的线程将该 HashMap 修改的情况,所以可以通过 containsKey(key)来做判断是否存在这个键值对,从而做相应的处理,也就不存在二义性问题。
也就是说,多线程下无法正确判定键值对是否存在(存在其他线程修改的情况),单线程是可以的(不存在其他线程修改的情况)。
ConcurrentHashMap的扩容加锁机制
ConcurrentHashMap 在扩容时会加锁,但并不是对整个数据结构加锁,而是采用了更加细粒度的锁机制。
在 ConcurrentHashMap 中,扩容操作是由多个线程协作完成的。它将数据结构分成多个段(Segment)或桶(Bucket),每个段或桶都可以独立地进行扩容操作,并且在扩容过程中只对正在进行扩容的段或桶加锁,而不会影响其他段或桶的并发访问。
这种细粒度的锁机制使得 ConcurrentHashMap 在扩容时仍然能够支持高并发的读写操作,大大提高了并发性能。相比之下,传统的 HashMap 在扩容时需要对整个数据结构进行加锁, 这会导致在扩容期间所有的读写操作都被阻塞,严重影响并发性能。
ConcurrentHashMap 能保证复合操作的原子性吗?
ConcurrentHashMap 是线程安全的,意味着它可以保证多个线程同时对它进行读写操作时,不会出现数据不一致的情况,也不会导致 JDK1.7 及之前版本的 HashMap 多线程操作导致死循环问题。但是,这并不意味着它可以保证所有的复合操作都是原子性的,一定不要搞混了!
复合操作是指由多个基本操作(如put、get、remove、containsKey等)组成的操作,例如先判断某个键是否存在containsKey(key),然后根据结果进行插入或更新put(key, value)。这种操作在执行过程中可能会被其他线程打断,导致结果不符合预期。
如果线程 A 和 B 的执行顺序是这样:
- 线程 A 判断 map 中不存在 key
- 线程 B 判断 map 中不存在 key
- 线程 B 将 (key, anotherValue) 插入 map
- 线程 A 将 (key, value) 插入 map
那么最终的结果是 (key, value),而不是预期的 (key, anotherValue)。这就是复合操作的非原子性导致的问题。
那如何保证 ConcurrentHashMap 复合操作的原子性呢?
ConcurrentHashMap 提供了一些原子性的复合操作,如 putIfAbsent、compute、computeIfAbsent 、computeIfPresent、merge等。这些方法都可以接受一个函数作为参数,根据给定的 key 和 value 来计算一个新的 value,并且将其更新到 map 中。